|
Saurabh Kulshreshtha Hi, I am a Machine Learning Engineer at Meta on the Brand Advertising team. Previously, I worked as a Senior Data Scientist at Fidelity Investments, AI Center of Excellence, where I worked on machine learning and large language models and prior to this I worked as a Research Scientist at Meta. I received my PhD with focus on Large Language Models and Applied NLP from University of Massachusetts in 2022, where I was advised by Anna Rumshisky. In the summer of 2021, I was an intern at Facebook in News Signals team where I worked on news personalization and integrity. In 2019, I worked at Amazon Alexa with the Natural Language Understanding (NLU) team where I worked with Ching-Yun Chang and José Luis Redondo García.
Email /
CV /
LinkedIn |

|

ResearchI'm interested in natural language processing, machine learning, optimization, and large language models. My research has had focus on information extraction, question answering, analysis of vector spaces in large language models and cross-lingual transfer learning. |
|
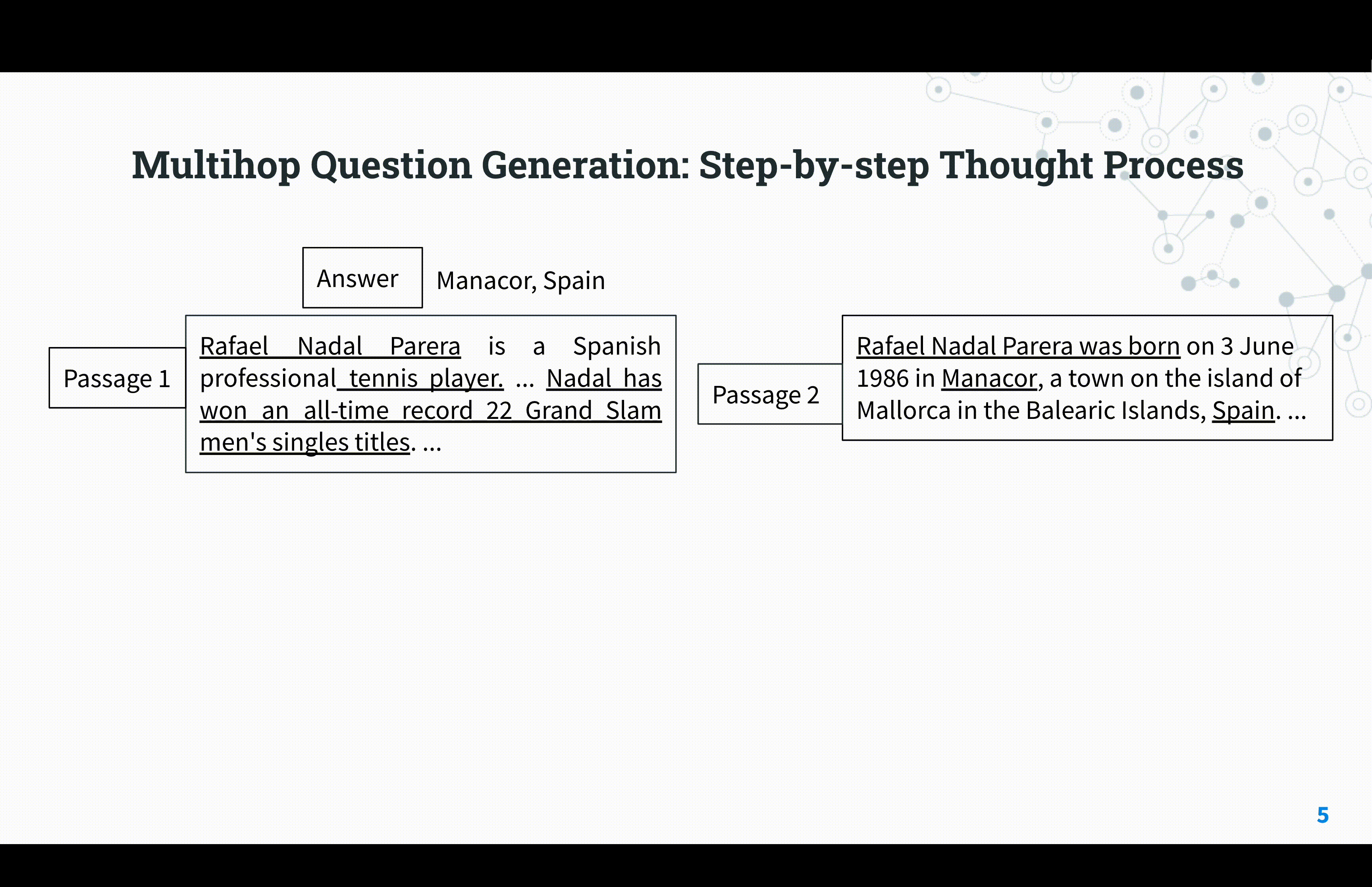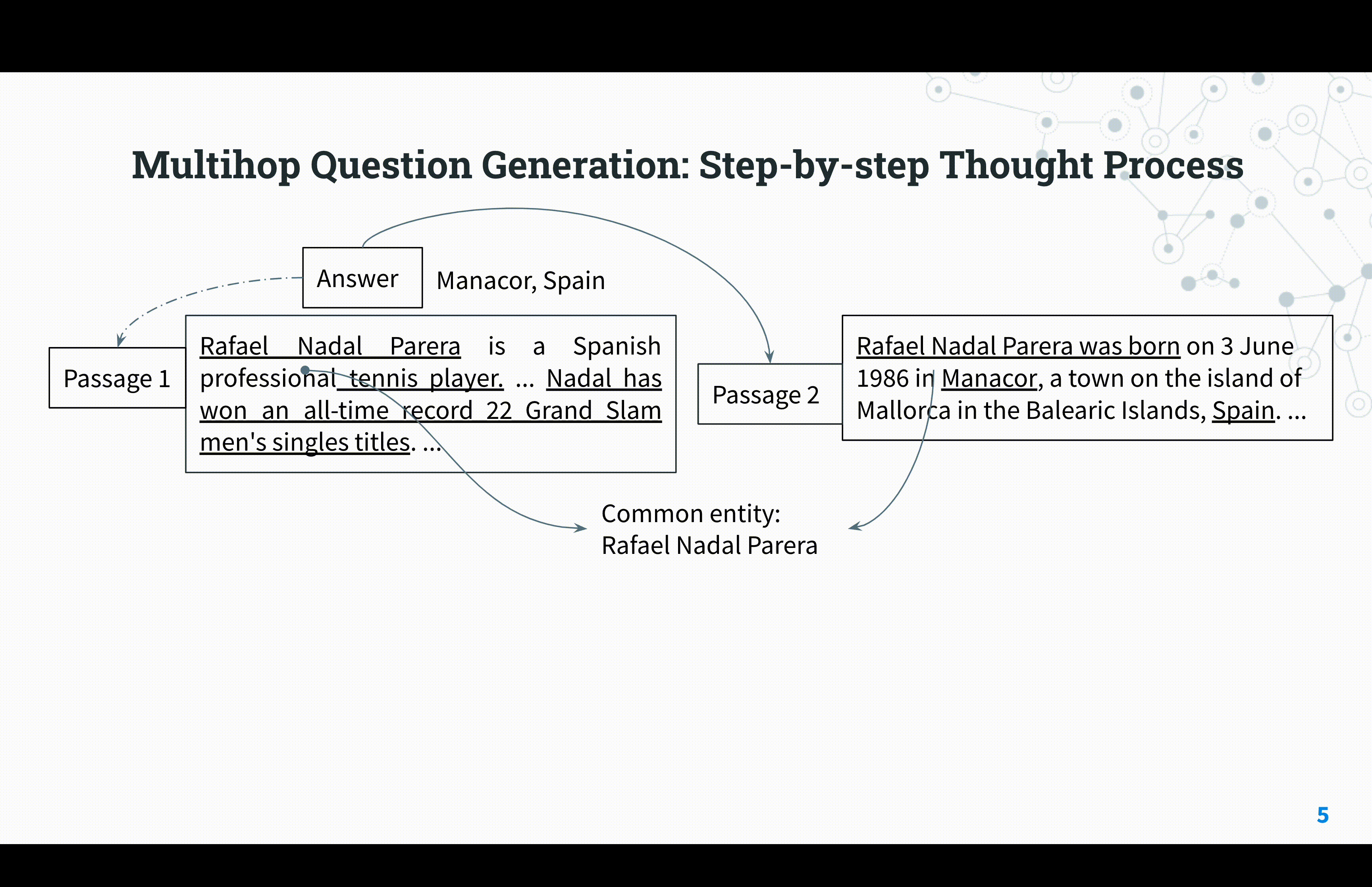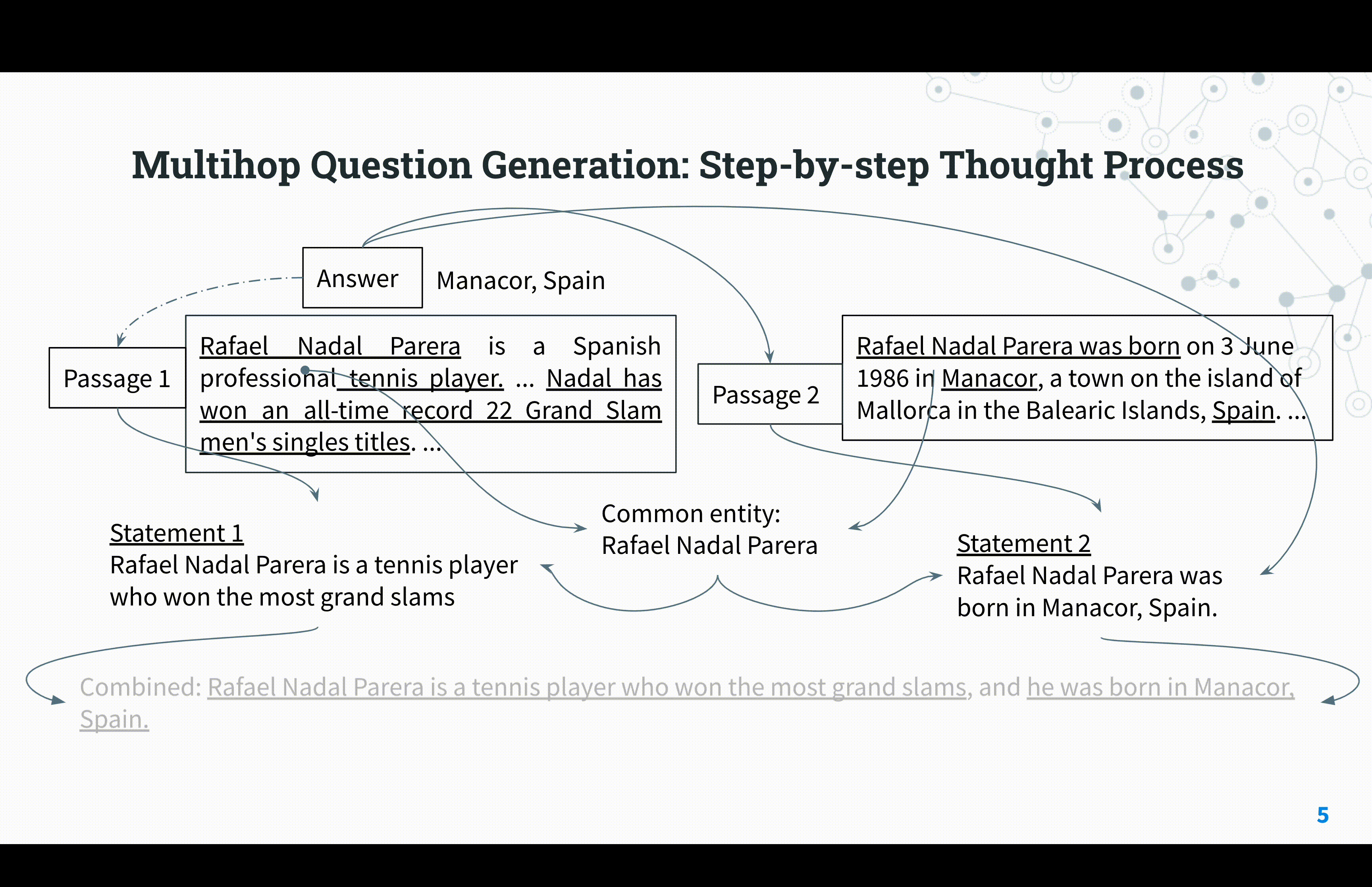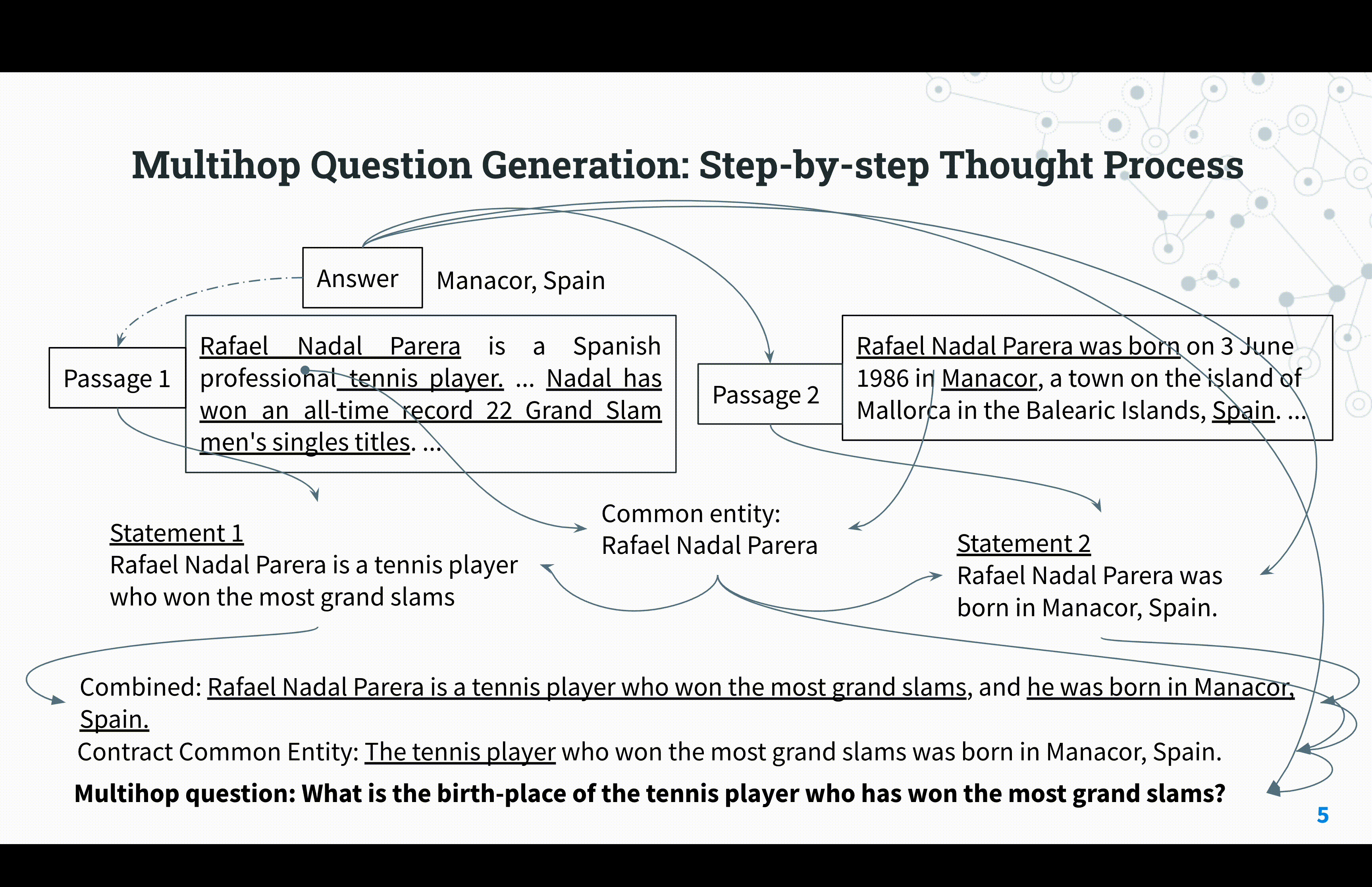
Reasoning Circuits: Few-shot Multihop Question Generation with Structured Rationales
Saurabh Kulshreshtha, Anna Rumshisky ACL Workshop, 2023 arXiv We present a new framework for multi-hop question generation that leverages a structured rationale schema to improve question difficulty control and performance under low supervision conditions, showing effectiveness even with modest model sizes. |

|
Down and Across: Introducing Crossword-Solving as a New NLP Benchmark
Saurabh Kulshreshtha, Olga Kovaleva, Namrata Shivagunde, Anna Rumshisky ACL, 2022 arXiv We introduce crossword puzzle-solving as a new natural language understanding task, providing a large-scale corpus collected from New York Times crosswords, releasing over half a million unique clue-answer pairs for open-domain question answering, and proposing both novel models and an evaluation framework for this task. |
|
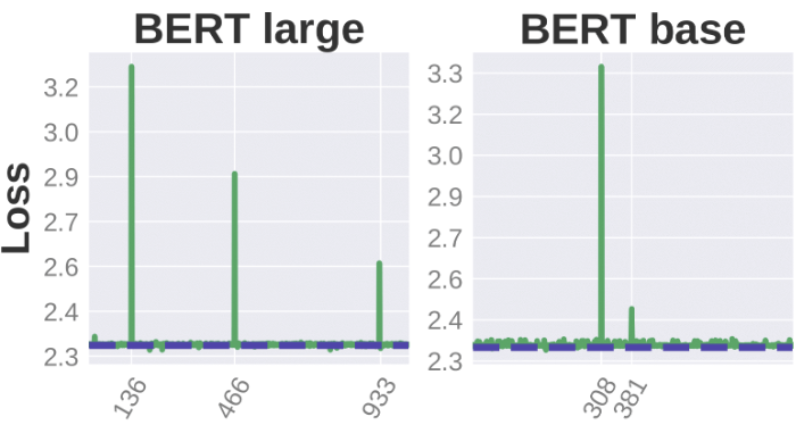
BERT Busters: Outlier Dimensions that Disrupt Transformers
Olga Kovaleva*, Saurabh Kulshreshtha*, Anna Rogers, Anna Rumshisky ACL, 2021 arXiv Our study challenges the notion of Transformer robustness to pruning by revealing that the removal of a tiny fraction of features in layer outputs, specifically high-magnitude normalization parameters in LayerNorm, significantly impairs the performance of popular pre-trained Transformer models like BERT, BART, XLNet, ELECTRA, and GPT-2. |
|
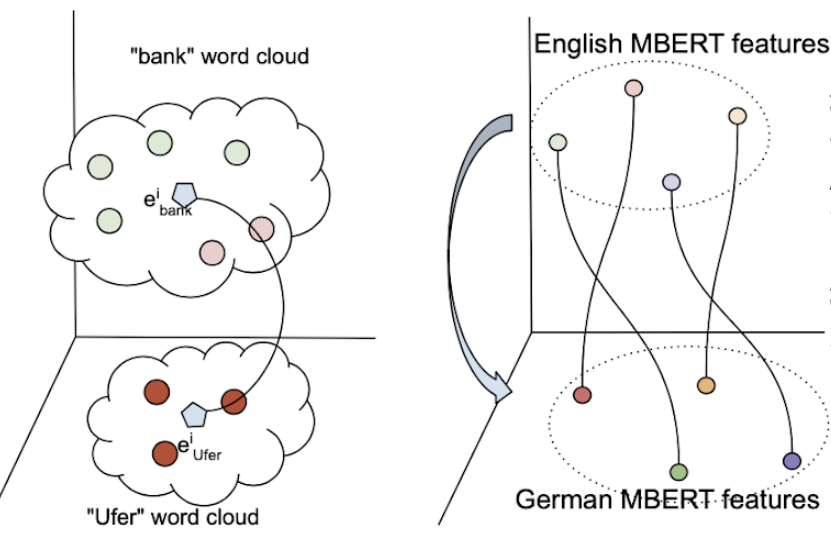
Cross-lingual Alignment Methods for Multilingual BERT: A Comparative Study
Saurabh Kulshreshtha, Jose Luis Redondo Garcia, Ching-Yun Chang EMNLP, 2020 arXiv Multilingual BERT shows reasonable zero-shot cross-lingual transfer capability, but aligning it with cross-lingual signal from parallel corpora or dictionaries using rotational or fine-tuning methods further improves performance, with the best alignment method depending on language proximity and task. |
|
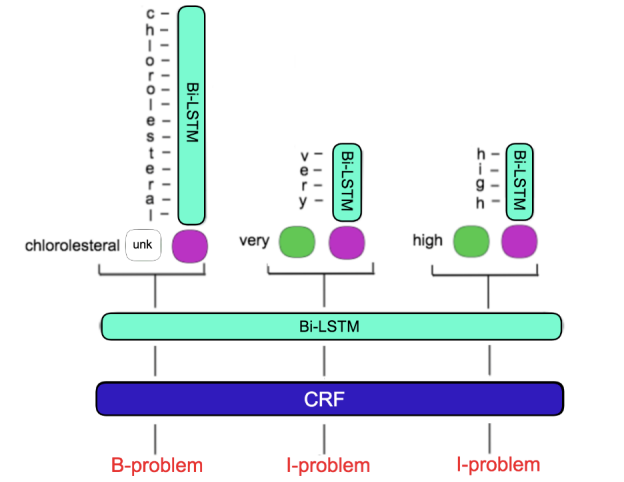
CliNER 2.0: Accessible and Accurate Clinical Concept Extraction
Willie Boag, Elena Sergeeva, Saurabh Kulshreshtha, Anna Rumshisky, Tristan Naumann NeurIPS Workshop (NIPS), 2017 arXiv CliNER 2.0 is an open-source tool using LSTM models to achieve state-of-the-art performance for extracting clinical concepts from text to aid downstream tasks, with pre-trained models available for public use. |
|
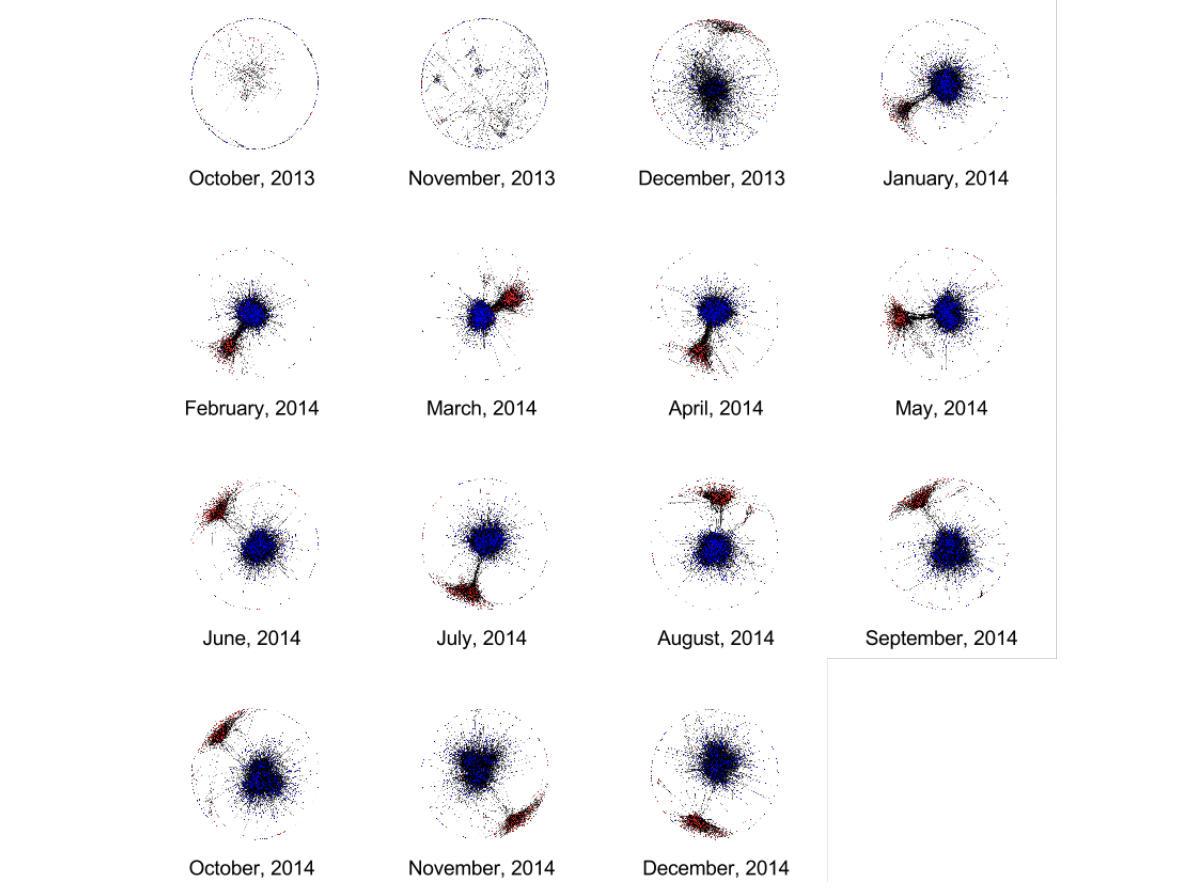
Combining network and language indicators for tracking conflict intensity
Anna Rumshisky, Mikhail Gronas, Peter Potash, Mikhail Dubov, Alexey Romanov, Saurabh Kulshreshtha, Alex Gribov International Conference on Social Informatics, 2017 Springer This work uses network polarization, sentiment analysis, and semantic shift to analyze the dynamics of social conflict over time, using social media data from the Ukraine-Russia Maidan crisis as a case study. |
|
* Equal Contribution / Website template from this great guy! |